Short answer: Yes, it is possible to run fewer MPI processes (e.g., 10) and use the remaining cores (out of 48) for OpenMP threads—but you must set up the process–thread mapping (affinity) correctly so that each of your 10 MPI ranks can actually use multiple cores, rather than all being pinned to just 10 total cores.
Below are the key points and how to do it in practice.
1. Understanding the “idle core” issue
When you do:
mpirun -np 10 [other options] ./lmp_IGO -in in.file
without specifying how to bind or map processes, Open MPI (or Intel MPI, etc.) might place each of those 10 MPI processes on 1 core each by default (depending on the MPI library’s defaults). That would leave the other 38 cores truly idle. You then set
export OMP_NUM_THREADS=4
for instance, but if each MPI process is bound to just 1 core, all 4 threads fight for that one core—rather than spreading out across 4 cores.
Hence you see 10 busy cores and 38 idle cores.
2. Letting 10 MPI processes each use multiple cores
To actually distribute your 10 processes across the 48 cores, you need to:
- Remove or adjust “-np” so that it matches your desired total number of MPI ranks. (Here you do want 10, so that’s fine.)
- Tell MPI how to place (map) those 10 processes across the available cores.
- Tell MPI (or the OpenMP runtime) how to bind—or not bind—those processes so each process can indeed use multiple cores.
Example approach
- Option A: Bind to “none” (i.e., do not pin processes to specific cores). Then the kernel scheduler is free to place threads on any available core:andThis tells MPI to create 10 processes, each allowed to run on any of the 48 cores. Your 4 OpenMP threads per rank should be able to spread out across unused cores.
- export OMP_NUM_THREADS=4
- mpirun -np 10 --bind-to none --map-by node \ ./lmp_IGO -in in.file
- Option B: Bind to “socket” or “numa” but in a way that 10 processes still fit. For instance, if you have 2 sockets × 24 cores = 48 total cores, you might do:
- ppr:5:socket says: “put 5 MPI processes on each socket”—total of 10.
- --bind-to socket means each MPI process (and all its OpenMP threads) can use all 24 cores in that socket. Five ranks on a 24-core socket implies some sharing, but that might be fine for your workload.
- If each rank uses OMP_NUM_THREADS=4, that’s 10×4 = 40 threads total, so you still have 8 physical cores essentially “unassigned” or available for extra overhead.
- mpirun -np 10 --map-by ppr:5:socket --bind-to socket \ ./lmp_IGO -in in.file
Either way, the critical point is that you must not do “bind-to core” with multiple OpenMP threads—because that confines each rank + threads to one single core.
3. The multiplication check: do you really want all 48 cores used?
- If you use -np 10 and OMP_NUM_THREADS=4, that’s a total of 40 “threads of execution.” You’ll leave 8 cores idle. Maybe that’s okay if your simulations actually run faster that way (due to lower MPI overhead).
- If you prefer to use all 48 cores, you could do -np 12 and OMP_NUM_THREADS=4 = 48 total, or -np 4 × OMP_NUM_THREADS=12, or many other combinations that multiply to 48.
Benchmark different splits to see which runs your problem the fastest. Sometimes fewer MPI ranks + more threads is better; other times pure MPI or a different split is best.
4. Summary
- It is not “impossible” to use “idle” cores for OpenMP threads—you just need proper mapping/binding.
- If you see only 10 cores busy (and the rest idle), likely the MPI ranks are bound one-per-core.
- Use “bind-to none” or “bind-to socket/numa” with a suitable “map-by …” so each rank can access multiple cores.
- Check the total (MPI × OMP) vs. your 48 physical cores to avoid oversubscription unless you specifically want it.
- Test different splits (e.g., 4×12, 6×8, 8×6, 12×4, 16×3, 24×2, etc.) to find the sweet spot for your simulation.
테스트 해보자
mpirun -x OMP_NUM_THREADS=6 -np 8 --bind-to none --map-by node ./lmp_IGO -in TI.in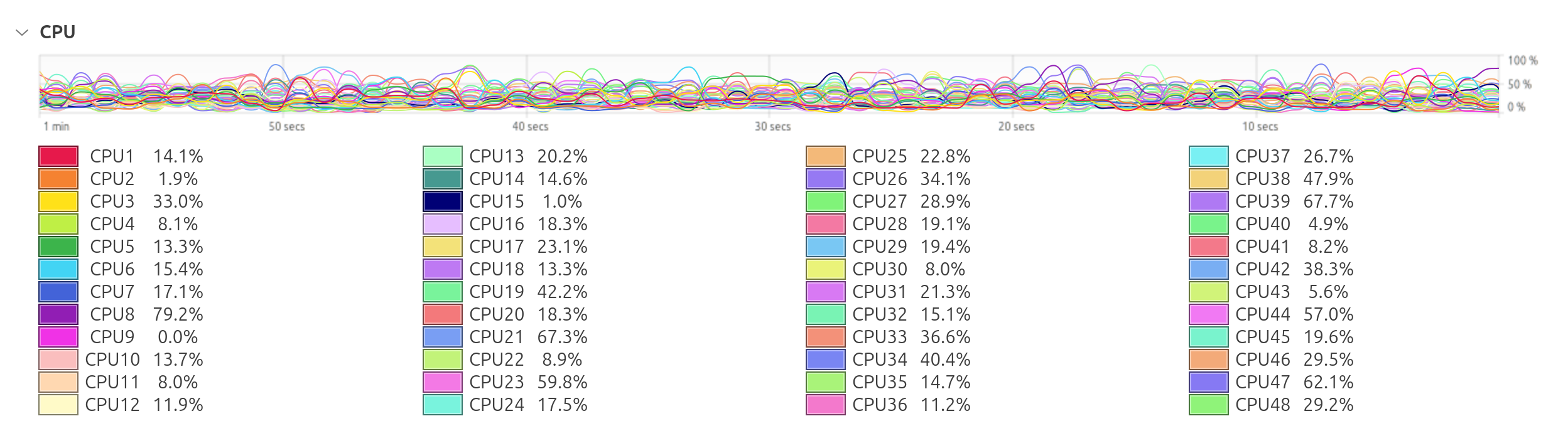
mpirun -x OMP_NUM_THREADS=6 -np 8 --bind-to socket --map-by ppr:4:socket ./lmp_IGO -in TI.in

mpirun -x OMP_NUM_THREADS=6 -np 8 --bind-to numa --map-by ppr:4:socket ./lmp_IGO -in TI.in
무식하게 돌리면 이것도 돌아간다
mpirun -x OMP_NUM_THREADS=20 -np 16 --bind-to numa --map-by ppr:8:socket ./lmp_IGO -in TI.in'OpenMPI' 카테고리의 다른 글
| OpenMPI with AOCC (2) | 2025.01.23 |
|---|---|
| Another (2) | 2025.01.09 |
| TEST (0) | 2025.01.09 |
| OpenMPI 설치 with CUDA Support (2) | 2024.12.31 |